컴퓨터 네트워크 #8
목차
- 라우팅의 속성
- 라우팅의 전략
- 최소비용 알고리즘
ARPANET의 세대별 라우팅
라우팅
네트워크의 효율적 이용을 위하여 서로 통신하는 종단 노드들 사이에 네트워크를 통과하는 경로를 찾는 것.
어떻게 네트워크에서 가장 효율적인 경로로 데이터를 전송/수신 할 것인가
라우팅의 속성
속성
- 정확성
- 단순성
- 견고성 : 네트워크의 문제가 발생하거나, 과부하가 걸려도 어떤 경로를 통해서라도 패킷을 전달할 수 있는 능력
- 안전성 : 변화하는 상황에 대처하는 능력 , 너무 늦게 반응하거나 루프되는 현상이 없어야 한다.
- 공정성 : 모든 통신이 공정하게 처리될 것
- 최적성 : 처리율을 최대화 하는 최적의 방법
- 효율성 : 라우팅 기술은 처리,전송 오버헤드를 초래하는데 이 오버헤드를 대응하는 비용이 견고성, 공정성으로 얻는 이득에 비해 얼마나 적은가 (라우팅 오버헤드 최소화)
루프 현상
어떤
노드A가 현재 과부하가 걸려있다고 하자. A는 지금 패킷을 너무 많이 받아서FULL된 상태이다.경로배정을 할 때, A가 꽉 차있음을 인지하고 모든 패킷을 B노드로 돌리는 알고리즘이 있다면, 얼마가지 않아 B가 과부하 상태가 될 것이다.
또한 A는 패킷을 받지 못해 놀고있는 상태가 된다.
이후 같은 현상이 반복될 것이고
A과부하→B과부하→A과부하→B과부하… 같은 현상이 벌어지면서 영원히 과부하가 풀리지 않는루프 상태가 된다.따라서 이러한 루프 현상을 피하는 라우팅을 해야한다.
공정성 vs 최적성
처리율을 최대화 하려면 가장 가까운 종단 스테이션에 해당하는 패킷부터 처리하면 된다.하지만 이렇게 처리를 할 경우 가장 먼 거리에 있는 스테이션은 패킷을 받는데 굉장히 오랜시간이 걸리고 이는 공정성에 어긋난다.
따라서 좋은 라우팅은 이 둘 사이에
절충점(trade-off)를 찾아야 한다.라우팅의 성능 기준
- 최소 홉 수(최단 경로) : 가장 짧은 경로를 통해서 목적지에 도착하는 것
- 최소 비용 : 가장 비용이 적은 경로를 통해서 목적지에 도착하는 것
노드의 정보발생원
- 없음 : 정보가 없이 라우팅을 한다. ex. 플러딩, 무작위 방식
- 로컬 : 노드 자기 자신이 가진 정보로 경로를 판단한다.
- 인접 노드
- 경로상의 모든 노드
- 모든 노드 (중앙집중식 라우팅)
갱신 시간(update timing)
정보원과 라우팅 전략의 함수.
이용 정보가 많고 갱신 빈도가 높을수록 네트워크는 더 우수한 라우팅 설정이 가능하지만, 자원 소모는 더 심해진다.
라우팅 전략
고정적 라우팅
- 모든
발신지-목적지 노드쌍에 대해영구적인 경로가 존재 - 데이터 그램, 가상회선과 차이가 없다.
- 유연성이 떨어지고, 네트워크 혼잡/실패에 취약하다.
네트워크 상황
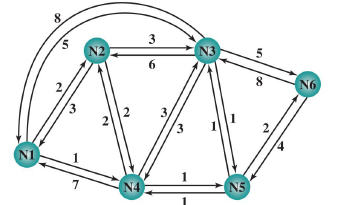
영구적 경로

표를 보면 1번 노드에서 3,4,5,6번 노드로 갈려면 4번 노드를 거치게 영구적 경로설정이 되어있다.
네트워크가 아무리 혼잡해도 무조건 정해진 경로로 이동한다.
- 모든
플러딩
- 패킷이 들어온 경로를 제외한 모든 출력 경로로 패킷을 재전송
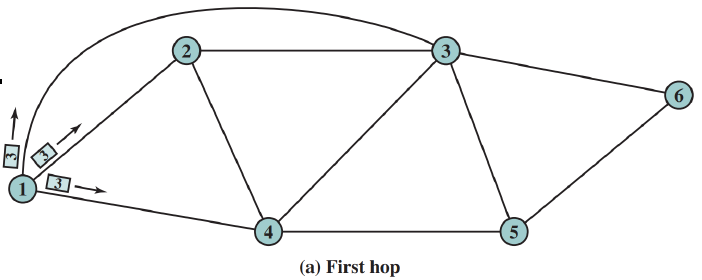
- 패킷에 홉 카운트 정보를 기록하고, 홉 카운트가 0 이되면 패킷을 폐기한다.
- 경로가 존재한다면 항상 수신지에 도착하며, 최소 홉 경로가 항상 존재한다.
- 무슨 일이 있어도 패킷이 전송되기 때문에, 긴급한 메시지나 방송에 이용된다.
- 홉 카운트가 노드를 지날때 마다 하나씩 줄어들고 0이 되는 순간 모든 노드에서 패킷을 폐기한다.
무작위
한 노드에서 전송가능한 모든 노드들에 대해 확률을 무작위로 다르게 설정하고, 확률에 따라 무작위로 전송한다.
적응적 라우팅
네트워크 상황에 따라 라우팅 결정이 변하는 방식, 따라서 노드 간의 네트워크 상태정보 교환이 필수이다.
교환 정보량이 높을 수록 라우팅 품질이 높아지지만, 네트워크 부하도 커지게 된다.
반응성이 크면 진동(루프) 이 크고, 반응석이 작으면 진동이 작다.
최소비용 알고리즘
다익스트라
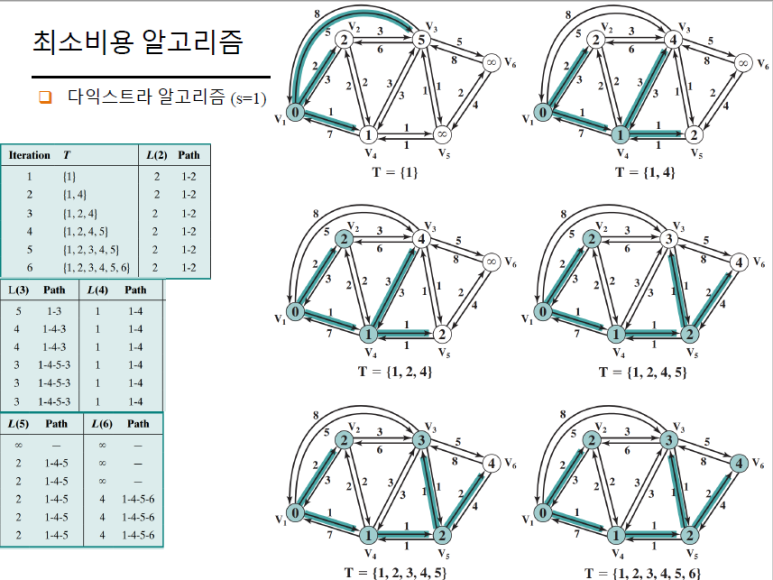
동작 방식
- 출발지 노드에서 갈 수 있는 모든 노드에 비용을 적는다. 갈 수 없는 노드는 무한대이다.
- 그 중 최소비용으로 갈수 있는 노드를 선택한다.
- 선택한 노드에서 1번을 다시 실행한다.
- 같은 노드에 대해 중복적으로 비용 체크를 했다면, 기존 탐색 비용과 새로운 탐색 비용을 비교한다.
- 기존 비용이 더 저렴할 경우 수정하지 않고, 기존 비용이 더 비싸다면 새로운 탐색 비용으로 바꿔서 기록한다.
- 새로갈 수 있는 노드들이 생기면 비용을 갱신한다.
- 더 갈 수 있는 경로가 없으면, 가장 최근에 체크한 노드로 돌아온다.
- 탐색하지 않은 노드중에 가장 최소비용으로 갈 수 있는 노드를 선택하고 위 과정을 반복한다.
- 더 이상 탐색하지 않은 노드가 없다면 종료
벨만 포드
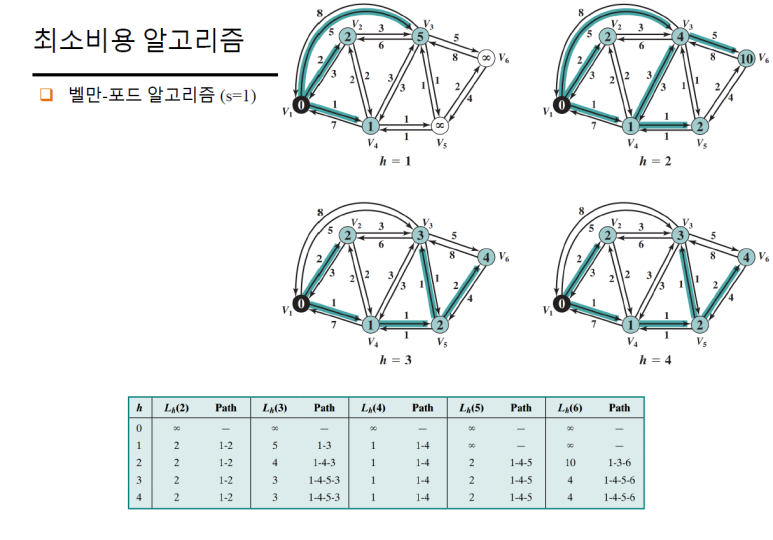
동작 방식
- 출발노드에서
s번에 걸쳐 갈 수 있는 노드들을 순차적으로 탐색, 시작 시s=1 s를 증가시켜 가면서, 기존 체크한 비용보다 새로 체크한 비용이 작으면 새로운 비용으로 갱신s=n일때와s=n+1일 때에 대해, 모든 노드들의 비용이 변화가 없으면 탐색 종료
- 출발노드에서
ARPANET의 세대별 라우팅
ARPANET
오늘날 인터넷의 기초가 된 예전의 패킷 교환망
1세대 : 거리 벡터 라우팅
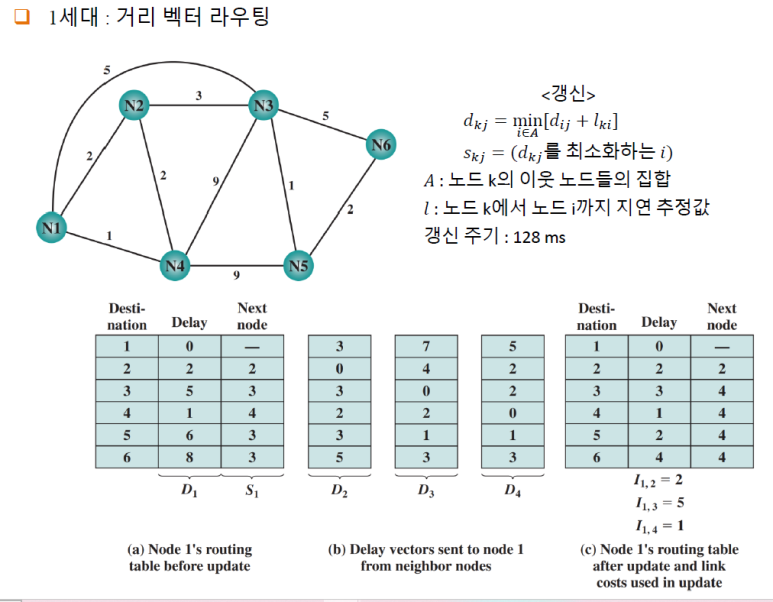
i(=1)번노드에서 갈 수 있는 모든 노드에 대해delay시간과, 그 노드를 갈 때 거쳐가야할 바로 다음 노드를 저장하는 방식이다.$D_i$ 는
i번노드를 시작으로 했을 때 기록된 delay 이다.모든 노드들은 주기적으로
(128ms)모든 이웃노드와 지연벡터(delay)를 교환한다.이 입력받은 delay를 근거하여, 임의의
노드 k는 다음과 같이 $d_{kj}$ 와 $S_{kj}$ 를 새로 갱신한다.$d_{kj}$ 는 노드 k에서 j까지 최소지연에 대한 추정값이다.
이 때 d(ij) 는 j와 연결된 모든 노드가 i 가 된다.
그리고 그 모든
i1,i2…. 노드들에 대해서 k에서 i까지 가는 최소지연의 추정값이 $l_{ki}$ 이다. s이 때 이 delay 를 최소화 하는
i값이 $S_{kj}$ 가 된다.ex
k=1,j=5이고, 노드 j와 연결된 노드는 3번,4번노드이다.그렇다면 min [ d(ij) + l(ki) ] 이므로 i = 3,4 가되고, k= 1 이 된다.
(
k노드 → 3번노드까지 가는 지연 추정값 +3번 → 5번(j)노드까지 가는 현재 추정값) 과(
k노드 → 4번노드까지 가는 지연 추정값 +4번 → 5번(j)노드까지 가는 현재 추정값)두 개를 비교해서
min, 작은 값을 골라 새로 갱신하는 것이다.그 때 3번 노드가 더 작다고 판단되었으면, $S_{kj} = 3$ 이 된다.
2세대 : 링크 상태 라우팅
1세대의 거리 벡터 라우팅은 다음과 같은 문제점이 발생한다.
- 링크 속도를 고려하지 않음
- 패킷이 대기열 진입할 때까지의 가변적인 처리시간을 고려하지 않음
- 혼잡/지연 증가에 느리게 반응
따라서 링크 상태 라우팅은 Time stamp를 이용하여 직접 지연을 측정한다.
- 각 노드에서의 지연 =
출발시간-도착시간+전송시간+전파지연 Ack신호 수신 시에만 지연 측정,Nack신호 수신 시 지연 재측정- 측정 주기 = 10초
- 지연 측정 결과 변동이 있다면, 플러딩 방식으로 다른 모든 노드에 전파
- 지연 결과 수신 시, 각 노드는 다익스트라 알고리즘을 통해 라우팅 표를 새로 갱신한다.
하지만 2세대도 아래와 같은 문제점이 발생한다.
- 부하가 큰 경우 측정값이 엉뚱하게 나온다 (진동 발생)
1번에 루프현상이 발생한다.
A에 과도한 트래픽이 몰려 과부하가 발생했을 때 A의 지연시간은 기하급수적으로 커지기 때문에 모든 노드들이 순간적으로 또 다른 노드인 B를 향해가도록 경로 재배정을 할 것이다.
그럼 A와 B사이에 루프, 네트워크 혼잡, 트래픽 진동이 발생하게 된다.
3세대에서는 링크 비용 계산 방법을 추가하였다.