컴퓨터 네트워크 #10
목차
- 혼잡(congestion)과 혼잡제어
- 혼잡제어 기법
- 혼잡제어와 트래픽 관리
- 패킷 교환망,
TCP에서의 혼잡제어
혼잡(Congestion) 과 혼잡제어
혼잡현상이란 네트워크를 통해 전송되는 패킷의 수가 네트워크의 패킷처리 용량 한계에 도달할 때 발생한다.
네트워크의 특정 노드의 I/O port에서는 들어오는 패킷을 저장하고 출력하는 역할을 맡는다.
저장은 보통 고정 크기에 버퍼를 통해 하거나, 버퍼링을 할 수 있는 메모리 공간을 사용한다.
이 과정에서 포트는 입력 버퍼로 패킷을 수신 → 조사, 경로결정 → 출력 버퍼로 패킷 이동을 하는 과정을 거친다.
이 과정에서 (조사 + 경로결정 + 패킷이동 + 전송) 과정보다 (입력) 과정이 빠르다면 더 이상 입력을 받을 수 없는 상황이 되어버린다.
이것을 혼잡이라고 부르고, 이러한 현상을 해결하기 위한 기법을 혼잡제어 기법이라고 한다.
이상적인 성능에서는 버퍼의 크기가 무한대이고, 혼잡제어 오버헤드가 없다고 가정한다.
이 경우에는 무한대의 입력이 들어와도 버퍼가 무한대로 저장가능하기 때문에, 네트워크는 정규화된 처리율을 유지한다.
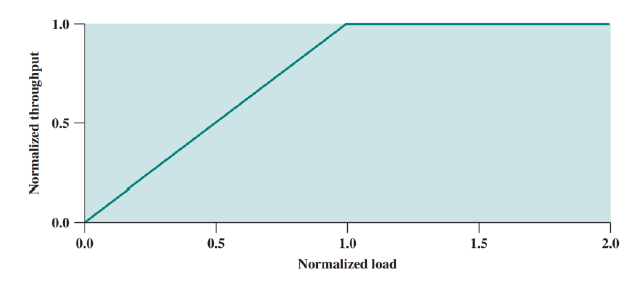
X축은 정규화 부하 이다.
실제 성능에서는 유한 버퍼이므로 버퍼 범람이 발생하고, 혼잡제어 오버헤드로 인한 네트워크 용량이 소모된다.
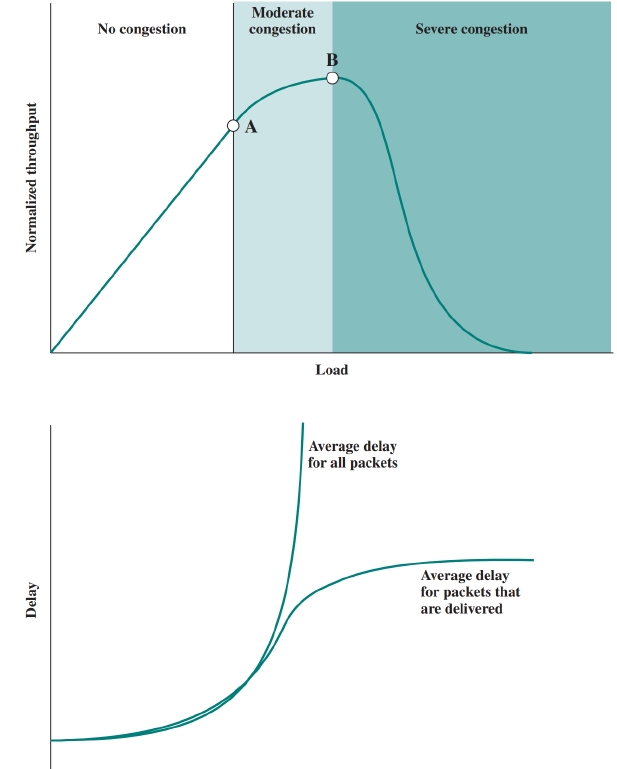
위 그래프에서 X축(Load) 는 부하이고, y축(Normalized Throughput)은 정규화 처리율이다.
초기에는 부하가 커짐에 따라 처리율이 일정하게 증가한다.
A지점이 되면서 그래프가 완만하게 꺾이는데, 이는 처리율의 증가량보다 부하의 증가량이 더 커지기 떄문이다.
이 원인이 바로 네트워크가 혼잡상태에 들어가기 때문이다.
치솟지 않고 완만하게 꺾이는 이유는 혼잡제어에 의해 네트워크가 부하를 균등화 시키기 때문이다.
이러한 혼잡제어 기법을 사용함에도 불구하고 트래픽이 많아 부하가 계속 증가한다면 B지점 노드는 버퍼의 크기를 넘어서는 패킷들을 폐기한다.
그럴 경우 발신지는 이 패킷을 재전송하고 부하는 다시 증가하며, 더 많은 버퍼가 포화되는 악순환이 계속된다.
혼잡제어 기법
후면압박(backpressure)
포화된 노드가 더 이상 패킷을 오지 못하게 뒤로 전달시키는 방법이다.
예를 들어 노드 6번에서 포화가 일어나면 6번은 5번 노드에게 다음 명령을 전달한다.
노드 6번 → 노드 5번
“패킷 전송속도를 늦추거나, 더 이상 패킷을 보내지 마시오”
이 명령을 받은 노드 5번은 자신이 전송할 노드를 하나 잃었으므로, 자신도 패킷을 덜 받을 필요가 있다.
따라서 노드 5번도 자신에게 송신하는 모든 노드들에게 같은 명령을 전달한다.
이는 역순으로 계속 전달되고 최종적으로 발신지까지 전파된다.
초크 패킷(choke packet)
혼잡이 발생한 노드에서 발신지에게 역으로
초크 패킷을 전송한다.이 패킷은 발신지로부터 송신율을 낮추라는 메시지를 담고 있다.
이 송신율은 더 이상 초크 패킷을 받지 않을 때 까지 줄어든다.
후면압박과의 차이는, 후면 압박은 바로 이전 노드에게 전송하지만, 초크 패킷은 발신지로 전달된다.
혼잡노드에서 발신지로 전송되는 과정에서 거치는 중간 노드들은 이 초크 패킷의 담긴 메시지를 열어보지 않는다.
단순히 발신지로 전달만 한다.
묵시적 혼잡 신호방식
만약
발신지 A가수신지 B로 어떤 패킷들을 보낸다고 하자. 중간 네트워크는 현재 혼잡이 발생한 상태이다.그렇다면 패킷은 B까지 전달되지 않고 폐기되거나, 지연시간이 증가될 것이다.
따라서 역으로 A가 지연시간의 증가와 패킷 폐기 사실을 인지한다면, 묵시적으로 혼잡이 발생했다는 것을 알아차릴 수 있다.
이를 인지한 A는 발신을 하지 않거나, 송신율을 줄이게 된다.
그러므로 이 방식은 네트워크 노드에 대해서 어떠한 혼잡제어도 요구하지 않는다.
혼잡제어를 하는 주체는
종단 스테이션이다.명시적 혼잡 신호방식
네트워크가 종단 노드들에게 혼잡하다고 통보하는 방식이다.
이 때 통보를 발신지로 하면 역방향, 수신지로 하면 순방향이라고 한다.
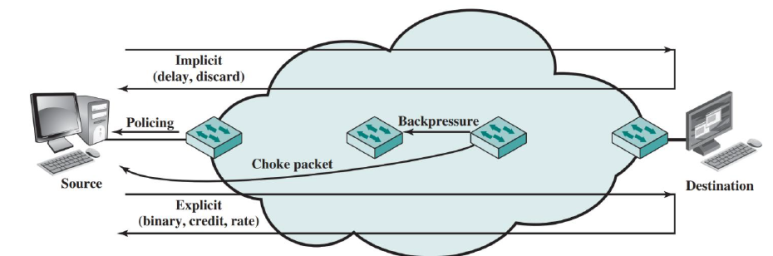
Implicit(묵시적), Explicit(명시적)
이 떄 통보 방식은 다음과 같다.
이진(Binary)
혼잡 노드가 패킷을 전송하면서, 패킷의 한 비트를 설정한다.
이 비트를 받은 종단 시스템은 트래픽 흐름을 줄인다.
신용 기반(Credit based)
신용이란 발신지가 얼마나 많은 패킷을 전송할 수 있는가를 가리키는 값이다.
신용을 전부 소모할 경우, 발신지는 추가 데이터 전송을 할 수 없다.
발신지가 추가 데이터 전송을 하려면 추가적 신용이 할당되기를 기다려야 한다.
전송율 기반(Rated based)
발신지의 전송율에 제한을 두는 방법이다.
발신지는 이 제한을 넘어서는 속도로 데이터를 전송 할 수 없다.
네트워크 상의 노드는 혼잡제어를 위해 전송율을 제한하는 메시지를 발신지에게 전달할 수 있는 권리를 가진다.
혼잡제어와 트래픽 관리
결국 혼잡 상태가 일어나는 원인은 트래픽 증가로 인해 네트워크에 부하(버퍼의 포화)가 걸리기 때문이다.
트래픽을 관리하는 기법에 따라서도 혼잡을 줄일 수 있다.
공정성
모든 패킷들의 흐름은
동일한 혼잡 수준에서 평가 받기를 원한다.예를 들어, 내가 마지막에 도달한 패킷이라고 폐기 당하면 이는 공정하지 못할 수 있다.
이를 개선하기 위해 각 노드들은 연결마다 또는
발신지-목적지쌍마다 상호 분리된 대기열을 유지하는 방법을 사용하기도 한다.이는 높은 트래픽 부하를 가진 대기열 패킷을 자주 폐기하게 한다.
즉, 나중에 온 패킷을 폐기하는 것이 아니라, 트래픽 부하가 높은 대기열의 패킷을 폐기하는 것이다.
서비스 품질(QoS)
서로 다른 트래픽은 서로 다르게 취급하는 방법이다.
사용자들이 실시간 생방송을 볼 때에는 지연에 민감하다.
예를 들어 월드컵을 하는 도중에 영상이 지연되서 온다면 큰 문제가 되지만, 영상의 일부가 잠깐 분실되서 오는 정도에는 둔감하게 넘어갈 수 있다.
반대로 우리가 어떤 중요한 메일을 받는 경우에는, 조금 늦게 도착하는 것은 괜찮지만 내용이 분실되는 것은 큰 문제가 된다.
즉 이는 모든 트래픽은 다른 우선순위를 가짐을 의미한다.
따라서 네트워크가 혼잡한 기간 동안, 우선순위가 더 높은 트래픽을 더 중요하게 관리해서 다른 서비스 품질을 제공해야 한다.
이를
QoS(Quaility of Service)라고 한다.같은 대기열에 늦게 도착한 패킷이라도 그 우선순위가 높다면 먼저 전송되는 것이다.
또한 대기열 마다 우선순위를 둬서 높은 우선순위의 대기열의 혼잡을 먼저 해소하게 하는 것도 가능하다.
예약(reservation)
네트워크와 사용자 사이에 데이터 전송율과 트래픽 특성을 규정하는 협정을 맺는다.
이 협정 안에 속하는 트래픽은
QoS를 보장하지만, 이외의 트래픽은 폐기하거나 최선의 방법으로 처리한다.현재 네트워크의 자원 상태가 새로운 예약을 충족시킬 수 없는 상황이라면, 새로운 자원 예약을 거부한다.
트래픽 감찰 또한 예약 기법의 한 종류이다.
Shaping and Policing(성형과 감찰)
QoS 에 어긋나는 패킷들을 식별하고 조치하는 방법이다.
어긋난 패킷을 식별했으면 헤더에 표시하거나, 낮은 우선순위를 주거나, 혹은 폐기할 수 있다.
이 방법에 사용되는 2가지 기법은
토큰 버킷(token bucket)과리키 버킷(leaky bucket)이다.토큰 버킷
일정한 크기(비트)의 버킷에 토큰을 저장한다.
이 때 토큰 생성기가 버킷에 토큰을 넣는 속도를
허용 전송률이라고 하고 버킷의 크기를허용 버스트라고 한다.어떤 트래픽이 네트워크로 진입을 하면 패킷과 같은 크기의 토큰을 요청하고, 이 토큰을 받은 패킷은 전송을 위해 대기한다.
만약 가용 토큰이 없다면 표시가 되어 대기되거나, 버퍼에 저장되거나, 혹은 폐기된다.
리키 버킷
전송되는 패킷을 담는 버킷을 두고, 전송율을 일정하게 제한하는 방식이다.
예를 들어 버킷의 크기가 30이고 초당 전송율이 5이다.
이 때 초당 15짜리 패킷이 들어온다면, 리키 버킷의 경우 초당 15중에 5를 전송하고 10을 버킷에 쌓아둔다.
이 때 쌓아두는 데이터는 버킷의 크기를 초과할 수 없다.
더 이상 데이터(패킷) 이 들어오지 않는다고 해도, 리키 버킷은 버킷이 빌 때 까지 초당 5의 전송율로 남은 데이터들을 계속 전송한다.
패킷 교환망, TCP 에서의 혼잡제어
패킷교환망에서 혼잡제어
- 초크 패킷
- 경로배정 (라우팅) 정보에 의존하는 방식
- 지연 측정을 위한 탐사 패킷 사용
- 노드들이 패킷이 통과할 떄 혼잡정보를 추가하는 방식
TCP의 혼잡제어
- 재전송 타이머 관리 (RTO)
RTO
RTT(Round Trip Time = 왕복지연시간)추정을 통해 왕복지연시간보다 조금 크게 재전송 타이머를 설정하는 방법이다.왕복지연시간보다 조금 늦게 패킷을 보내 혼잡을 제어하는 방법이다. 이 때 RTT를 추정하는 방법은 2가지가 있다.
단순 평균(ARTT)
K+1번째 전송한 세그먼트(패킷)에 대해 측정한 왕복시간을 다음과 같이 추정한다.$ARTT(K+1) = \frac{K}{K+1} \times ARTT(K) + \frac{1}{K+1} \times RTT(K+1)$
쉽게 말해서, K개의 세그먼트에 대해 측정한 왕복지연시간/세그먼트 개수(K개) 를 하면 된다.
우리가 일반적으로 아는 평균을 구할 때와 같은 방법이다.
지수 평균(SRTT)
SRTT 평균이 나오게 된 이유는 가중치에 있다.
즉 가장 최근에 보낸 패킷이 현재 네트워크에 가장 근접하므로, 최근에 보낸 패킷일 수록 가중치를 주는 것이다. 측정 방법은 다음과 같다.
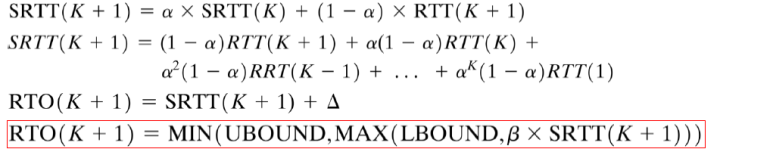
가중치를 결정하는 값이
a이다.K+1번패킷의 지수평균을 계산하는 경우,K번패킷까지의 지수평균에는 a를,K+1번의 패킷에는1-a를 곱해서 더해준다.이 식을 풀어서 쓰면 사진의 두번째 줄과 같이 나오고, 지수적으로 표현되기 때문에 지수평균이다.
RTO 는 RTT값보다 조금 크기 때문에 세번재 줄에서는 델타를 더해준다.
마지막 식의
UBOUND(Upper Bound)와LBOUND(Lower Bound)는 재전송 타이머 값에 대해 미리 지정해놓은 상한 값과 하한 값이다.K+1까지의 지수평균 * B(상수)와LBOUND(재전송 타이머의 하한선)중에 더 큰 값을,그 값과UBOUND(재전송 타이머의 상한값)중에 작은값을 선택해서RTO(K+1)을 정한다.a값은 보통
0.8 ~ 0.9, b값은1.3 ~ 2.0으로 둔다.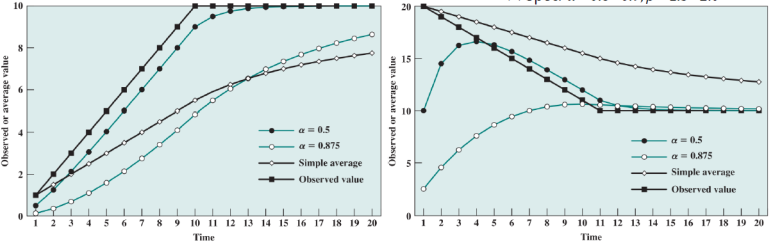
a = 0.5, 0.875 일 때와, Simple average(단순 평균) 일 때 RTO 값과 실제 측정값을 비교하는 그래프이다.
제이콥슨 알고리즘
위에서 추정한 RTO값은 RTT편차가 클 경우 지수평균도, 단순평균도 잘 맞지 않는다.
이런 RTT 값의 가변성을 추정해서, RTO 계산의 입력값으로 사용하는 방법이다.
이 때 추정하는 방법은 평균 편차를 이용한다.
일반 평균의 경우
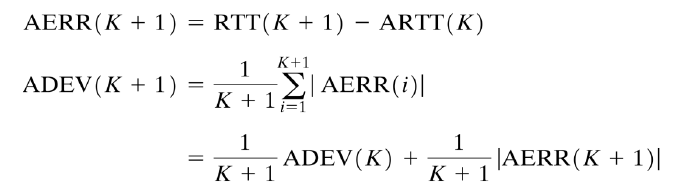
확률과 통계에서 평균절대편차를 구하는 방법과 같다.
각 패킷에서
RTT추정값 - RTT평균값의 절대값을 다 더해서, 패킷 수인K+1로 나누어주면 된다.지수 평균의 경우
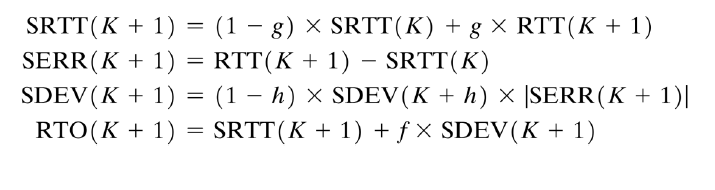
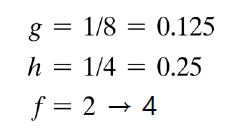
- SRTT : 지수평균 왕복추정시간
- 1-g : 지수평균에서의 a 값 ( 가중치 결정값 )
- SERR(K+1) : SRTT의 K+1 패킷에서의 편차 = 측정된 RTT(K+1) - K패킷까지의 지수평균
- SDEV : 제이콥슨이 제안한 SRTT 에서의 평균편차
- RTO(K+1) : 지수평균편차를 고려한 최종 지수평균 왕복추정시간
- h,f : 제이콥슨이 실제 실험 결과를 토대로 판단한 상수
제이콥슨 알고리즘에 따른 RTO 추정
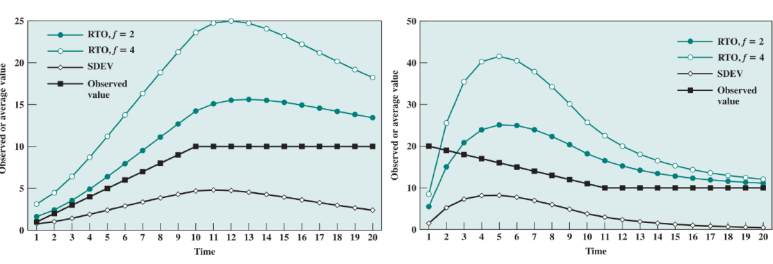
RTO 후퇴
다양한 발신지에서 임의의 세그먼트를 전송한다.
만약 이 세그먼트가 네트워크 혼잡에 의해 전달되지 못하고 유실되거나 지연되었다고 하자.
이를 눈치챈 모든 발신지는 동시에 세그먼트를 재전송하게 되고, 이는 네트워크 혼잡을 더 크게 만든다.
따라서 RTO 후퇴는 재전송을 할 때 마다 RTO 시간을 증가시키는 방법이다.
이것을
후퇴(backoff)과정이라고 부른다. 증가시키는 방법은 재전송 시 RTO 값에 상수 값 q를 곱해주는 것이다.가장 보편적으로 사용하는 q값은 2이다.
카른 알고리즘
어떤 세그먼트도 재전송하지 않는다면, 제이콥슨 알고리즘은 정확한 값을 추정할 것이다.
하지만 재전송을 고려한다면 다음과 같은 문제점이 발생한다.
어떤 세그먼트가 재전송되었다고 하자. 그럼 RTT 값은 첫번째 전송에 대한 RTT 와 재전송에 대한 RTT 2개가 존재한다.
하지만 TCP 송신은 이 2가지 경우를 구별하지 못한다. 이로 인해 두가지 문제점이 발생한다.
1번
두 번째 전송에 대한 확인응답(ACK신호) 를 첫번째 전송에 대한 확인응답 신호로 착각할 수 있다.
이 경우 측정시간이 너무 길게 측정될 것이다.
결과적으로 재전송 프로세스의 지연 증가 현상이 발생한다.
2번
첫 번째 전송에 대한 확인응답(ACK신호)를 두번째 전송에 대한 확인응답 신호로 착각할 수 있다.
이 경우 측정 시간이 너무 짧게 측정될 것이다.
결과적으로 추가적인 재전송 발생해 혼잡심화 현상이 발생한다.
카른 알고리즘은 다음과 같은 방법으로 문제의 해결법을 제안한다.
- SRTT 와 SDEV 갱신에 있어 재전송 세그먼트에 대해 측정한 RTT를 사용하지 않는다.
- 재전송이 일어났을 때 RTO 후퇴를 사용한다.
- 재전송 된 적이 없는 세그먼트에 대한 확인응답이 도착할 때까지, 뒤따른 세그먼트에 대해서는 후퇴 RTO값을 사용한다.
윈도우 관리
느린 출발 - 혼잡 회피
확인응답이 수신될 때마다 윈도우를 점차적으로 확장시키는 방법이다.
AWND= MIN(CREDIT, CWND) 를 사용한다.여기서
AWND는 동적 윈도우(Actual window),CWND는 혼잡 윈도우(Congestion window)를 의미한다.CREDIT 값은 수신 가능한 데이터 양/세그먼트 크기 로 정의한다.
수신 가능한 데이터 양은 수신단에서 미리 알려준다.
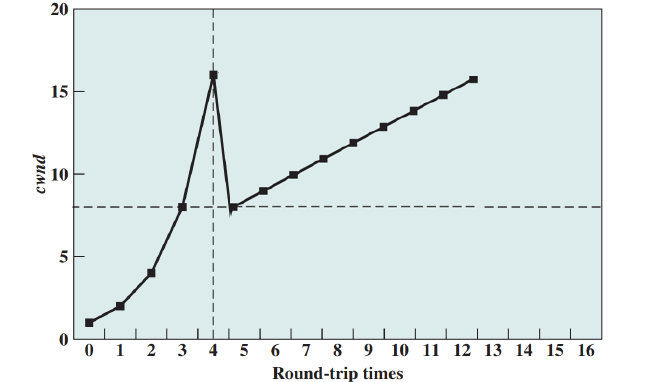
새로운 연결이 설정되면 cwnd = 1 로 초기화 한다.
TCP 는 MIN [CREDIT, CWND] 만큼 세그먼트를 전송할 수 있다.
따라서 1개의 세그먼트를 전송한다. 이후 확인응답을 기다린다.
CWND는 느린 출발의 경우
선형적으로(1,2,3,4...)증가하는게 맞지만, 실질적으로 CWND 값은 2배씩 증가한다.(1→2→4→8…)이유는 선형적으로 증가할 경우, 너무 느린속도로 증가하게 된다.
CWND 값은 증가하다가
Time-out이 일어나고, 이 때 CWND를 1로 초기화 함과 동시에 임계점(ssthresh = Threshhold) 를 Time-out 이 일어난 시점의 CWND 의 절반으로 설정한다.이후에는 임계점까지는 지수적으로 증가하고 임계점 이후로는 선형적으로 증가하는 방식을 취한다.
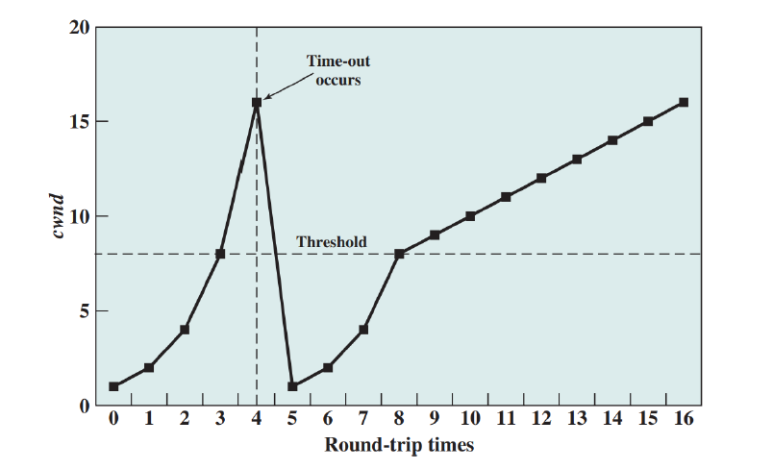
예를 들어 타임아웃이 18에서 발생했다면, ssthresh = $\frac{18}{2}$ = 9 가 된다.
그렇다면 CWND의 증가는 다음과 같이 이루어진다.
1 → 2 → 4 → 8 → 9 → 10 → 11 → ... → 18빠른 재전송
발신지에서 1,2,3 총 3개의 세그먼트를 한번에 송신했다고 하자.
이 때 2가 지연되어서 수신자는 1,3 세그먼트만 받았다.(혼잡 상황)
이 경우 수신지는 발신지에게 마지막으로 수신된 순서 내 세그먼트에 대한 ACK를 송신한다.
위의 상황에서는 1에 대한 ACK 송신을 한다.
세그먼트는 계속 송신될 것이므로
4,5,6,7...세그먼트가 추가로 도착할 것이다.이 때 여전히 2번 세그먼트가 도착하지 않았다면, ACK송신을 계속 반복해서 보낸다.
발신지는 한 세그먼트에 대해 N번이상 중복 ACK 신호를 받았다면, 해당 세그먼트를 재전송한다.
2번 세그먼트가 조금 늦게 도착하는 경우(지연) 도 있으므로, N을 신중히 선택해야 한다.
빠른 회복
느린출발에서
CWND를1로 초기화 하지 않고, 해당 CWND 를 절반으로 줄인다.그리고 이후 선형적인 증가시킨다. 이 방법은 지수 증가의 느린 출발과정을 생략할 수 있다.