[PIE] PieNet 논문 리뷰
Personalized Image Enhancement
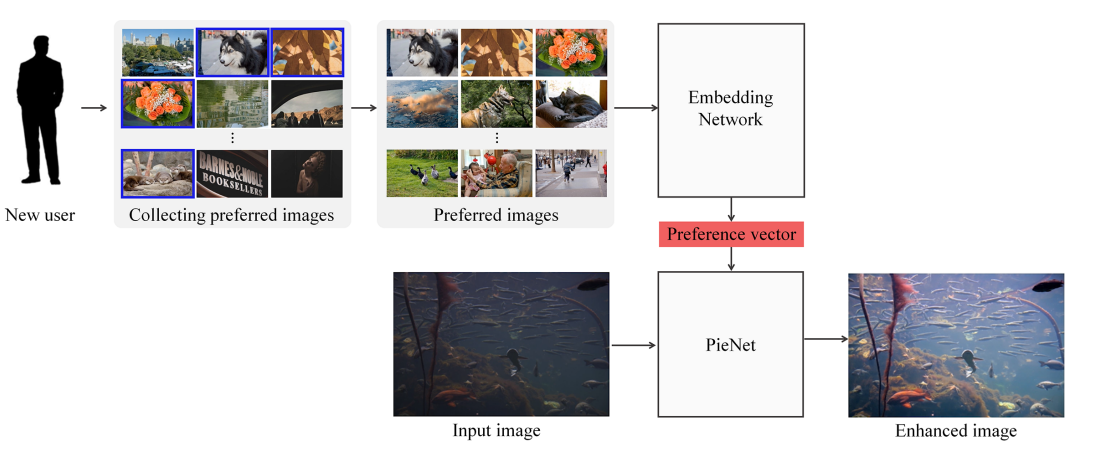
PIE task는 크게 두 가지 단계로 구분할 수 있습니다.
첫 번째는 Image에서 style을 얻는 과정이고 , 두 번째는 Image Enhancement 과정에서 style 을 자연스럽게 적용하는 것 입니다. 이 과정을 두 개의 네트워크 (style-network, Enhancemnet Network) 를 각각 학습하는 모델이 있고, End to End 로 한번에 학습 하는 모델이 있습니다.
PieNet은 먼저 style-network 를 학습한 뒤, style network의 Parameter를 fix 하고 Enhancement를 학습하는 두 단계 학습 과정을 이용합니다.
위 사진에서 New user → Collecting Preferred Images → Preferred Images → Embedding Network 가 첫 단계의 학습 과정이고, Input Image → Enhanced Image 까지가 두 번째 학습 과정입니다.
Introduction
현대의 이미지는 Camer Sensor, Dynamic Range, Distort Color tone 등에 의해서 손상됩니다.
쉽게 말해서 카메라로 현실을 촬영했을 때 사진으로 변환되는 과정에서 렌즈, 왜곡 보정 등에 의해 손상이 생긴다는 것 입니다.
이미지를 보정(Enhancment) 하는 방법은 SW (포토샵, Lightroom 등) 를 이용한 전문가의 보정, 고전적인 방법, 딥러닝을 이용한 Enhancement model 들이 있습니다.
하지만 실제로 Image를 보정하는 것은 개인마다 취향이 다르기 때문에 한 가지 방법으로만 보정하는 것은 Personalize Preference를 반영하지 못합니다. 또한 이런 분야의 딥러닝 모델이나 연구가 활발하게 이루어지고 있지 않아 성능이 부족합니다.
따라서 논문에서는 사용자의 선호도를 나타내는 ‘Preference vector’ 를 얻어내고 이를 이용해 이미지를 개선하는 방법을 사용합니다.
Deep Metric Learning
Metric Learning이란 어떤 데이터 간의 유사성을 판별하고, 거리를 학습하는 방법입니다.
논문에서는 Metric Learning을 통해 사용자의 Preference vector를 얻는 Embedding Network(space)를 학습합니다. 어떤 feature가 Expert A가 개선한 이미지와 거리가 가까워지고 나머지 Expert 와는 멀어지도록 학습하는 방식 입니다.
이렇게 학습된 Embedding Network는 다음에 새로운 사용자가 자신의 선호 이미지를 입력으로 넣어준다면, 해당 이미지에 대한 Preference vector를 출력으로 내보낼 수 있게 됩니다.
논문에서는 Metric Learning 에서 triplet loss를 사용하고 있습니다. triplet loss는 가까워져야 하는 data를 positive, 멀어져야 하는 데이터를 negative 라고 했을 때, postive, negative 와의 유클리디언 거리 distP, distN 을 구한 후 (distP - distN + margin) 을 Loss로 사용하는 방법입니다.
실제로 이 방법이 PieNet 모델에서 어떻게 사용되었는지는 Architecture 부분에서 살펴보겠습니다.
Architecture - Style Embed Network
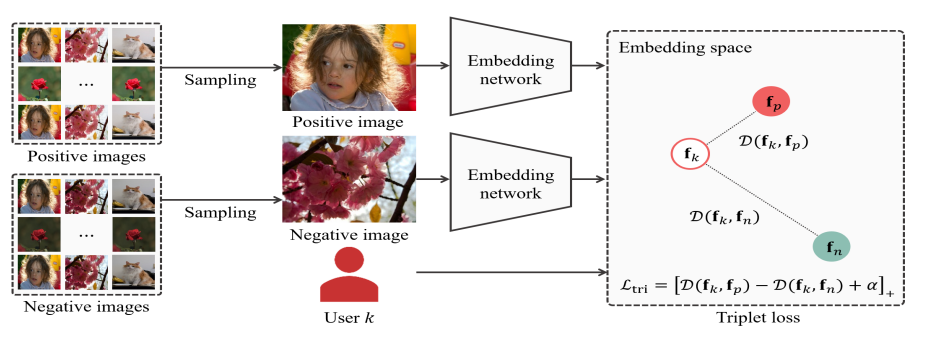
먼저 $N$ 장의 Training Image 와 $K$ 명의 User 가 있습니다.
K명의 유저는 각자 N장의 이미지 Style에 대해 ‘좋다(positive)’ 와 ‘나쁘다(negative)’ 를 결정합니다. 이를 수식으로 표현하면 아래와 같습니다.
여기서 $i$ 는 image의 index, $y_i$ 는 모든 유저에 대한 i번째 image 의 label vector를 의미합니다. 이 때 $K$번째 유저가 $i$번째 이미지를 ‘선호’ 한다면 $y_{iK} = 1$ 이 됩니다.
위의 내용에 기반해서 user $K$ 의 선호(positive) 이미지 집합은 $I_p$ , 비선호 이미지 집합은 $I_n$ 으로 표현할 수 있습니다.
이제 $I_p$ 와 $I_n$ 을 twin embedding Network 에 입력으로 넣어 output feature 인 $f_p, f_n$ 을 얻습니다. 이 때 twin embedding Network는 ImageNet으로 Pretrained 된 ResNet18을 사용합니다. 또한 postive image set 과 negative image set 은 해당 ResNet18의 가중치를 공유합니다.
이제 User $K$ 의 preference Vector 만 있다면 우리는 Deep Metric Learning 에서 언급한 triplet loss를 사용할 수 있습니다. 논문에서는 $K$ 의 preference Vector를 훈련 시 임의의 random vector로 초기화 한다고 합니다. 이 때 random value 로 초기화된 Preference vector는 $I_p$ 와 동일한 차원을 가져야 합니다.
이제 얻은 $f_p, f_n, f_k$ 를 바탕으로 아래 수식을 통해 Triplet Loss를 계산하고 역전파 합니다. 수식에서 []는 활성화 함수를, $\alpha$ 는 $margin$을 의미합니다.
Loss가 감소하려면 $D(f_k, f_p)$ 는 감소하고 $D(f_k, f_n)$ 은 증가해야 합니다. 따라서 $f_k$ 는 $f_p$ 와의 거리는 가까워지고, $f_k$ 는 $f_n$ 의 거리는 멀어지는 방향으로 학습이 됨을 알 수 있습니다.
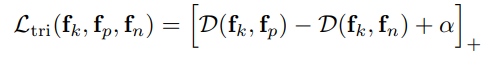
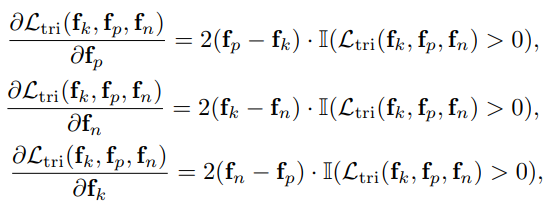
Embed-Network 의 학습 과정을 알아보았습니다. 실제 Training 과정의 입력, 모델 등에 대한 detail 은 Implement 부분에서 다루겠습니다.
Architecture - PieNet
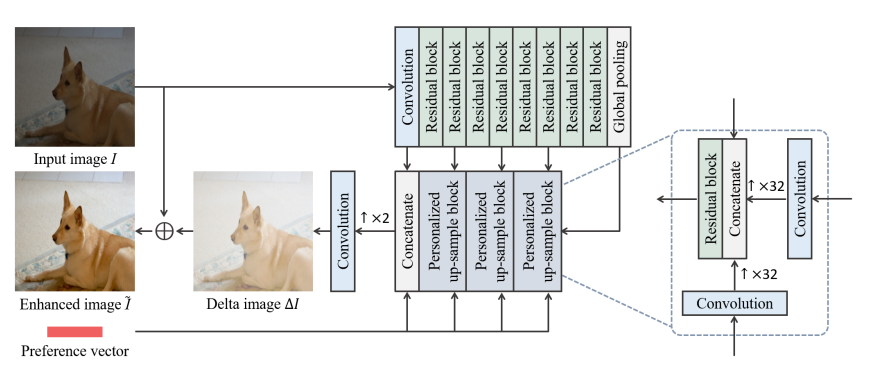
PieNet 은 Encoder-Decoder 구조를 가지고 있습니다.
Encoder에서는 RGB Image 를 Input 으로 받아 Conv x 1, Residual Block x 8, Pooling layer를 통과합니다. 이 때 conv,2,4,6,pooling layer의 output feature는 Decoder와 연결됩니다. 앞 layer에서 나오는 feature는 conv를 덜 진행한 만큼 local information을, 뒷 layer에서 나오는 feature는 global information을 가지게 됩니다.
Decoder 과정에서는 이전 layer의 입력, Style-Network 에서 얻은 Preference vector, Encoder feature 를 입력으로 받는 PUB(Personalized up-sample Bolck)을 사용합니다.
PUB는 이전 layer와 Preference vector를 각각 conv을 통해 Up-sampling 한 후, concat, Residual 과정을 진행합니다. 3개의 PUB를 거친 후 4번째는 Residual Block 대신 Conv 을 진행해 Δ$I$ 를 얻은 후 Input Image $I$ 와 Add 를 거쳐 최종 Enhanced Image $\tilde{I}$ 를 얻습니다.
Loss
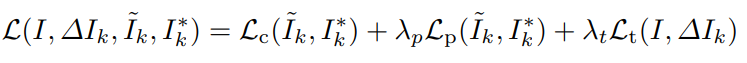
$I$ : Input Image ,
Δ$I_k$ : Delat Image = Decoder에서 얻은 user $K$ 의 Δ$I$
$\tilde{I_k}$ : Enhanced Image = user $K$의 $I + ΔI_k$ ,
$I_k^*$ : user $K$ 의 GT
$\lambda$ : Loss 가중치 (hyperparameter)
1) $L_c$ : color Loss
- L1 Loss : \(L_c(\tilde{I_k}, I_k^*) = {\vert \tilde{I_k} - I_k^* \vert}_{1}\)
Color Loss는 GT와 Enhanced Image 의 색상 차이를 학습하기 위한 Loss 입니다.
2) $L_p$ : perceptual Loss
- L1 Loss : \(L_c(\tilde{I_k}, I_k^*) = {\vert \tilde{f_k} - f_k^* \vert}_{1}\)
Perceptual Loss 의 경우 Enhanced Image 의 style-vector 가 user $K$ 의 선호도 벡터 근처에 있도록 합니다.
따라서 GT의 style vector는 곧 user $K$ 의 preference vector 가 됩니다.
$f_k^*$ 는 user $K$ 가 선택한 선호 이미지 N장을 Embed Network 에 입력으로 넣어 얻을 수 있고, $\tilde{f_k}$ 의 경우 Enhanced Image를 Embed Network 에 입력으로 넣어 얻을 수 있습니다.
3) $L_t$ : total variation Loss
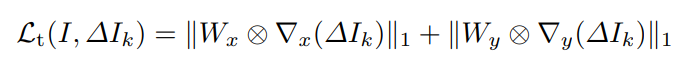
Total Variation Loss는 이미지의 spatial smoothness 를 유지하기 위해 사용됩니다. Enhancement task 에서 자주 사용되는 loss 입니다. 이미지의 임의의 어떤 픽셀은 인접한(상하좌우) 픽셀과의 차이, 즉 수평, 수직 미분값이 주변 다른 픽셀과 차이가 클 수록 큰 패널티를 부여합니다.
여기서 $W_x$, $W_y$ 는 $I$의 수평 수직 방향의 미분값에 exponential을 취한 값입니다. 수식은 아래와 같습니다.
Implement - Style Embed Network
Style Embed Network
Embed Network는 각 style별 $f_k$(preference vector)와 Twin Embed Network 로 구성됩니다.
$f_k$ 는 1 x 512 의 vector이고, 처음에는 랜덤값으로 생성됩니다. torch의 random 과 ParameterDict 기능을 이용합니다.
Twin Embed Network의 경우 ImageNet으로 pre-train 된 ResNet18을 사용합니다. 논문에 언급은 없지만 torch - ResNet18의 layer에 조금씩 변형을 준 듯 합니다.
preference vector (1x512) 와 거리를 계산할 수 있게 pooling, normalize 등의 작업을 거쳐 (batch_size x 512) 를 return 합니다.Training
style training 에서는 Adobe 5K Dataset의 Expert A~E 와 Lightroom으로 보정된 preset, 고전적인 방법으로 보정된 set, 3가지를 사용합니다.
먼저 각 style별 이미지를 가져온 후 랜덤 선택합니다. 이 때 선택한 style을 X라고 하겠습니다. 다음으로 X를 제외한 임의의 style 중 하나를 다시 랜덤하게 선택합니다. 이것을 Y라고 하겠습니다.
여기서 prefX 가 $f_k$ 이고 선택한 style X,Y의 image를 Embed Network에 통과시켜 얻은 feature vector가 $f_p$ , $f_n$ 이 됩니다.
위에서 얻은 $f_k, f_p, f_n$ 의 유클리디언 거리 distP 와 distN 을 계산합니다. 다음으로 distP - distN + a (=0.2) , ReLu를 거쳐 triplet Loss를 얻습니다. triplet loss를 역전파 시켜 twin Embed Network를 학습시킵니다.
순서대로 input, output을 보면 아래와 같습니다.- Input : style-X image A , style-Y image A
- Model : twin Embed Network
- Output : Positive feature - fP , Negative feature - fN
Implement - PieNet
이미지에 보이듯이 Encoder는 conv + ( Resblock x 8 ) + pooling 으로 이루어져 있습니다.
resblock 2,4,6,8 이후 3x3 conv 을 통해 downsampling 과정을 가집니다.
- Conv
- Input : Raw Image (256 x 256 x 3)
- Output : feature_0 (256 x 256 x 64)
- Residual Block 1,2 + Conv
- Input : feature_0 (256 x 256 x 64)
- Output : feature_2 (128 x 128 x 64)
- Residual Block 3,4 + Conv
- Input : feature_2 (128 x 128 x 64)
- Output : feature_4 (64 x 64 x 128)
- Residual Block 5,6 + Conv
- Input : feature_4 (64 x 64 x 128)
- Output : feature_6 (32 x 32 x 256)
- Residual Block 7,8 + Conv
- Input : feature_6 (32 x 32 x 256)
- Output : feature_8 (16 x 16 x 512)
- Global(Average) Pooling
- Input : feature_8 (16 x 16 x 512)
- Output : Encoder Output (1 x 1 x 512)
Encoder output 과 Preference vector 가 모두 1 x 1 x 512 으로 만들어졌습니다.
PUB(Personlized Upsample block)에서는 두 feature를 conv 을 통해 channel을 줄이고, upsamling, concat, resblock 을 반복합니다. 이 떄 upsampling 은 어떤 방법을 사용했다고 논문에 언급된 것이 없습니다. 그냥 torch에서 제공하는 방법 중에 하나 선택해서 upsampling을 진행하면 될 것 같습니다.
- PUB X 3 + Conv
- Input : Encoder Output(1 x 1 x 512), Preference Vector(1 x 1 x 512)
- Output : Delta Image Δ$I$ (256 x 256 x 3)
마지막으로 Input Raw Image 와 Δ$I$ 를 Add 해서 최종 Enhanced Image $\tilde{I}$ 를 얻습니다.
Implement - Detail
- Opitmizer : Adam
- Learning Rate : $ 1 \times 10^{-4} $
- Loss
- EmbedNet : Triplet Loss ( $ \alpha = 0.2 $ )
- Color, Perceptual, total : L1 Loss ( $ \lambda_{p} = 0.4 , \lambda_{t} = 0.01 $ )
- Batch size : 8
- Dataset : MIT-Adobe 5K Expert A~E
Result
Comparison
PieNet은 선호도 벡터를 이용합니다. Implement에서 선호도 벡터를 얻는 Embed Network 가 학습하는 과정을 알아보았습니다.
Test를 할 때는 2가지 방법으로 진행하는데, user $K$ 가 Positive set, 자신이 좋아하는 이미지 style만 입력으로 준 경우와 Positive 와 Negative를 모두 입력으로 준 경우입니다.
첫 번째 방식의 경우 단순히 Positive set 을 Embed Network에 입력으로 넣은 후 나온 feature vector 값을 평균내어 preference vector $f_k$ 를 결정합니다.
두 번째 방식의 경우 Embed Network의 parameter를 fixed 한 후, Positive sample 을 Embed Network 에 입력으로 넣으면서 $f_k$ 만 역전파를 진행합니다.
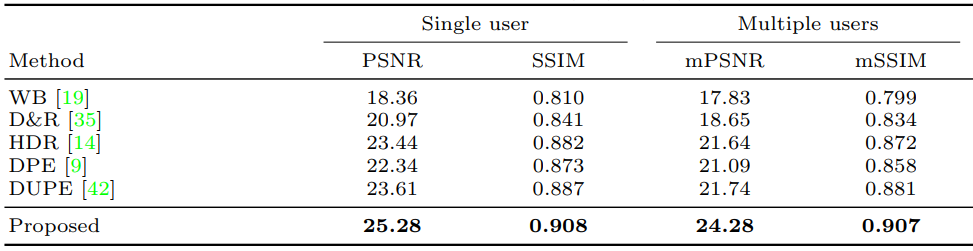
PieNet과 기존 Model 들을 두 가지 방법으로 비교하였는데, 다른 Model 들은 대부분 Expert C 의 결과만 가지기 때문입니다. 이에 따라 결과의 Single User 는 Expert C만 보정한 경우이고, Multiple User의 경우 다른 모델들을 각 Expert에 맞게 재학습시켜 A~E를 모두 비교한 경우입니다.
Ablation 1
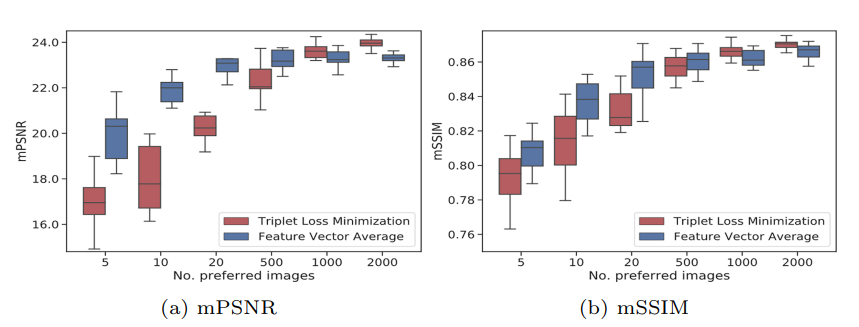
위 사진은 user $K$ 가 입력으로 넣어준 Positive Image 의 수 $N$에 따른 결과입니다. 가로축이 Image의 수 $N$이고, 세로축이 mPSNR 과 mSSIM 입니다. 빨간색 막대는 Positive set 과 Negative set을 모두 입력으로 넣고 Triplet Loss를 통해 $f_k$ 를 얻은 것이고, 파란색 막대는 Positive set 만 넣은 후 평균을 내서 $f_k$를 얻은 것 입니다.
실험 결과를 보면 Positive - Negative set을 이용한 경우 $N$ 의 수가 적으면 급격히 성능이 떨어지고, $N > 2000$ 일 때부터 Positive set만 넣은 결과보다 우수한 모습을 볼 수 있습니다. 또한, Positive set 만 있는 경우 $ N = 20 $ , 즉 선호 이미지 20장만 가지고도 충분히 좋은 preference vector를 얻을 수 있습니다.
다른 Enhancement 모델이라면 Expert C image로 학습을 시켰다면 Expert A style로 보정된 결과를 얻으려면 모델을 초기화한 후 다시 A image로 처음부터 다시 학습시켜야 하지만 PieNet의 경우 단 20장의 Expert A image를 통해 Expert A style로 보정하는 모델을 얻어낼 수 있습니다.
Ablation 2

상단 행은 PieNet 으로 얻은 결과이고, 하단 행은 각각 제안된 방법으로 얻은 결과(GT)입니다. LDR, WVM, RLM 은 Adobe Lightroom 에서 제공하는 보정 Preset 입니다. 상단 행을 보면 하단행 GT의 style에 맞게 잘 보정한 것을 볼 수 있습니다.
Ablation 3
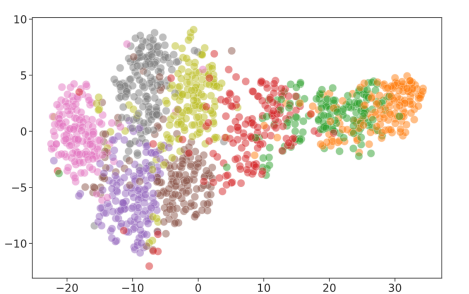
위 사진은 Embedding Network 를 통해 각 style 별 얻은 $f_k$를 t-SNE 기법을 통해 시각화한 것입니다. 시각화 과정에서 각 style의 이미지를 무작위로 100장 선정해 진행했습니다. 사진에서 볼 수 있듯이 각 style별로 feature들이 잘 clustering 된 것을 볼 수 있습니다.
Conclusion
PieNet은 사용자에 따라 선호하는 이미지의 style 에 따라 다른 결과를 얻습니다. 사용자가 선택한 선호 이미지를 style embed network를 이용해 feature로 얻어내 Enhancer와 접목시킴으로써 다른 style에 따라 재학습하는 것을 방지하였습니다.
후에 나온 다른 논문들이 언급하는 PieNet의 단점을 보면 style Embed Network에서 학습된 style이 아닌 new style의 경우 성능이 떨어진 다는 것, End-to-End 모델이 아니기 때문에 style feature가 이미지 style 보정에 핵심적인 역할을 하는 것이 맞는지 알 수 없다는 것, Embed network가 $f_k$를 얻는 과정이 Black-Box 하다는 것 정도가 있습니다.