[Object Detection] Co-DETR 논문 리뷰
Co-DETR (DETRs with Collaborative Hybrid Assignments Training)
Co-DETR 논문은 2023년 ICCV에서 나온 DETR(Detection Transformer) 기반 논문입니다.
아래 내용에 대해 알고 본다면 더 쉽게 이해하실 수 있습니다.
DETR
Faster R-CNN
Transformer Architecture
Feature Pyramid Network(FPN)
One-to-Many Label Assigment
One-to-one matching
Abstract
Co-DETR 논문에 대해 간단하게 요약하자면, DETR 기반 Object Detection 모델에 Collaborative를 이용해서 성능을 개선한다는 것입니다. 여기서 말하는 Collaborative란 다른 모델과의 협업을 의미합니다. 기존 DETR 모델에 다른 모델들을 결합해 DETR의 부족했던 부분을 보충하는 것이 메인 아이디어 입니다.
논문의 내용은 아래와 같습니다.
- 기존 one to many Label assigment를 가지는 모델 (Faster R-CNN, ATSS, FCOS, PAA, RetinaNet) 과 one-to-one set Matching의 DETR 기반 모델들의 한계
- one to many Label assigment & one-to-one set Matching 의 정밀한 분석
- Collaborative Head, 보조 헤드(Auxiliary Head)를 사용한 성능 향상
- one-to-one set Matching의 불안정성
Limit
one to many Label assigment란 하나의 객체에 다수의 box가 생성되는 것을 말합니다. DETR에서는 박스 1개와 G.T 하나를 매칭하기 때문에 one-to-many 한 과정이 발생하지 않습니다. 좀 더 쉽게 말하면, 이분 매칭을 하는 DETR 기반의 모델은 one-to-one set Matching이 되고, DETR 기반이 아닌 모델은 one to many가 많습니다.
one to many Label assigment one to many Label assigment 모델의 한계는 DETR 논문에서 언급하는 것과 같습니다. 너무 많은 hand-craft 작업입니다. hand-craft는 학습으로 도출되는 것이 아닌 작업을 의미합니다. 예를 들자면 하이퍼 파라미터나, IoU의 threshold(임계값) 등을 말합니다.
one-to-one set Matching DETR 모델의 한계는 ‘성능’ 이라고 말합니다. 결국 DETR 기반의 모델들은 단순화되고, 수작업이 줄어들었지만 one to many 모델들(Faster R-CNN)의 성능을 유의미하게 개선하지는 못했습니다.
Analysis DETR-based Detector
논문에 나오는 생소한 단어들이 있습니다. 아래 단어들입니다.
IoF - IoB Graph
latent feature(representation)
positive query
discriminability scores
discriminability score, IoF-IoB 그래프는 encoder와 decoder의 학습을 분석한 그래프 정도로 이해하면 좋습니다. 논문의 뒷 부분에서 다시 언급되기도 하고 수식을 보면서 이해하는 것이 더 쉽습니다. F는 Foreground로 객체가 존재하는 곳을, B는 Background로 객체가 없는 배경을 말합니다. 논문을 읽어보면 IoF-IoB 그래프가 더 높이 있을수록 더 좋다 라는 뉘앙스로 말하는 것을 보아, 배경과 객체를 잘 분리할수록 수치가 높게 나타난다 라고 추측해볼 수 있습니다.
positive query는 Faster R-CNN 에서 언급되는 ‘물체가 존재하는 query’ 입니다. 자세한 내용은 Faster R-CNN 논문을 참고하시면 좋을 것 같습니다. positive 는 객체가 있는, negative는 객체가 없는 정도로 해석 가능합니다.
latent feature는 직역하면 ‘잠재적 특성’ 인데 학습 과정 중에 드러나지 않는 숨겨진 특성, 모델의 중간 과정에서의 feature 등의 의미를 갖습니다.
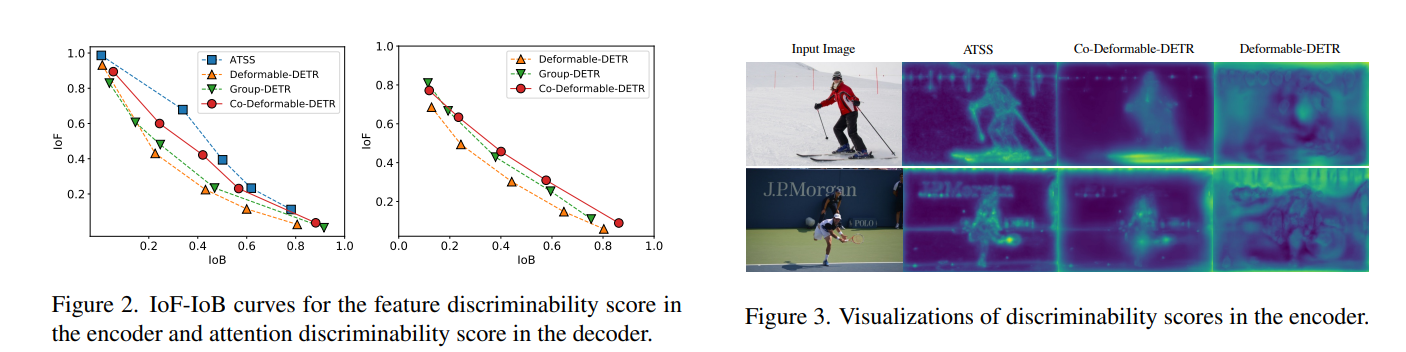
정리하자면 논문 저자들은 DETR-based model의 학습 과정 중 존재하는 latent feature(잠재적 특성, 잠재적 특성)를 어떤 수식을 통해 수치화 했습니다. 수치화 한 것이 discriminability score입니다. 그리고 discriminability score를 이용해 IoF와 IoB를 계산해 그린 것이 위 그래프입니다. 수식은 모두 논문의 뒷 부분에서 언급되기 떄문에 포스팅의 뒷 부분에 정리하였습니다.
Figure2,3를 보면 one to Many 기반의 ATSS 모델이 그래프도 위에 있으며, discriminability score 시각화 한 그림에서도 더 뚜렷하게 객체와 배경을 분리하고 있음을 알 수 있습니다.
이러한 문제점은 DETR based 모델들이 너무 적은 positive query (too few positive queries)를 가지기 때문이라고 주장합니다. 그렇다면 DETR base 모델이 ATSS보다 too few positive queries를 가지는 이유가 있어야 합니다. 논문에서는 이것에 대해 언급되는 것이 없습니다. 아래 주석은 제 생각일뿐 논문에서 언급된 것이 아닙니다.
One to many 가 DETR-based 모델들 보다 positive query가 많다고 합니다.
그렇다면 one to many 모델이 DETR-based 모델보다 무언가 많다는 뜻이라고 생각했습니다. 저는 그것을 객체에 대한 bounding box의 수라고 추측하고 있습니다.
one to many 모델은 하나의 객체에 대해 여러 개의 box가 생기고 마지막에 NMS를 통해 하나를 제외한 나머지를 제거하는 것을 알 수 있습니다. 이 말은 학습 과정에서는 많은 positive box를 가지고 있다는 것입니다. 하나의 객체 - 하나의 추측 과정에서 ‘하나의 추측’ 이 too few positive queries를 의미한다고 생각합니다.
논문에서 ‘한 객체에 대해 학습하는 query가 하나밖에 존재하지 않는 것’ 을 문제라고 말하는 것 같습니다.
CO-DETR Model
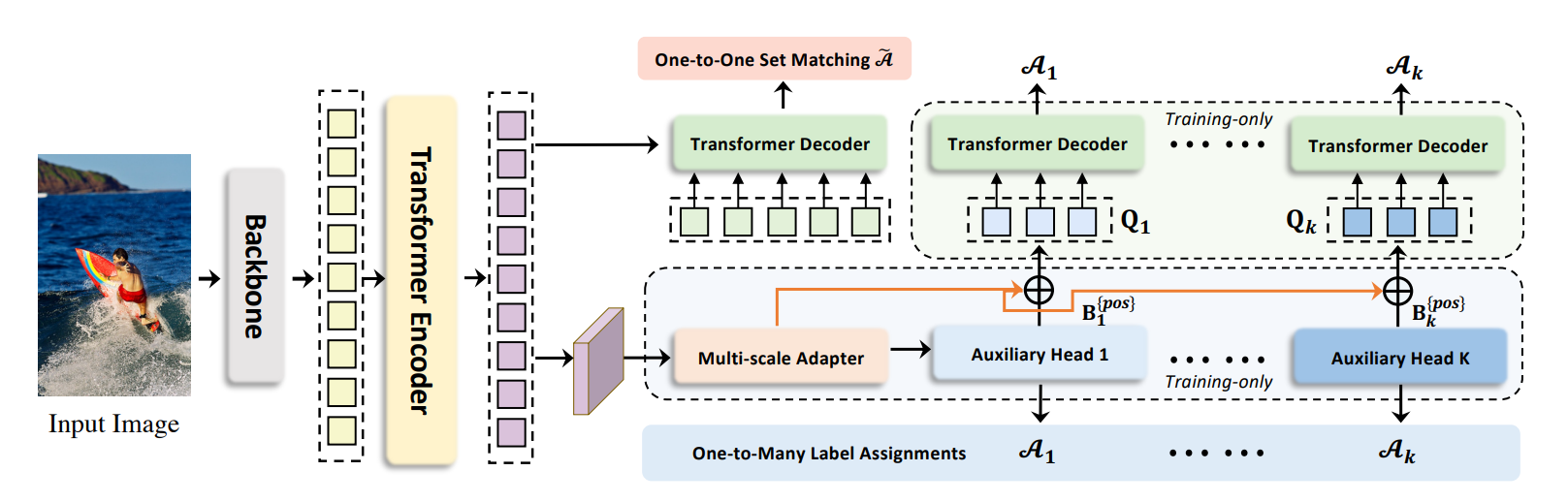
먼저 Encoder의 output까지는 DETR과 동일한 과정을 거칩니다.
DETR의 경우 Decoder의 input으로 객체의 수보다 충분히 큰 N개의 query를 넣습니다. decoder의 layer에서 이 query와 encoder의 output이 연산됩니다.
Co-DETR에서는 아무런 정보도 없는 N개의 query를 입력으로 넣는 것이 안좋다고 말합니다. 따라서 아래와 같은 방법을 제안합니다.
- Encoder의 ouput을 바탕으로 $F_{1}…F_{j}$ , 총 j개의 Feature Pyramid 를 생성합니다. 이 때 3x3 conv,stride=2 를 적용해 up(down)sampling 합니다. FPN 논문을 참고하시면 될 것 같습니다.
- 총 K개의 보조헤드는 $F_{1}…F_{j}$ 입력으로 받아 예측 $\hat{P_{i}}$ 를 얻습니다.
- $\hat{P_{i}}$ 와 $GT$를 바탕으로 논문의 표에 따라서 $P_{i}^{pos}$, $B_{i}^{pos}$, $P_{i}^{neg}$ 를 얻습니다.
- 3에서 얻은 것을 Query 수식에 적용해 Decoder의 input으로 사용합니다.
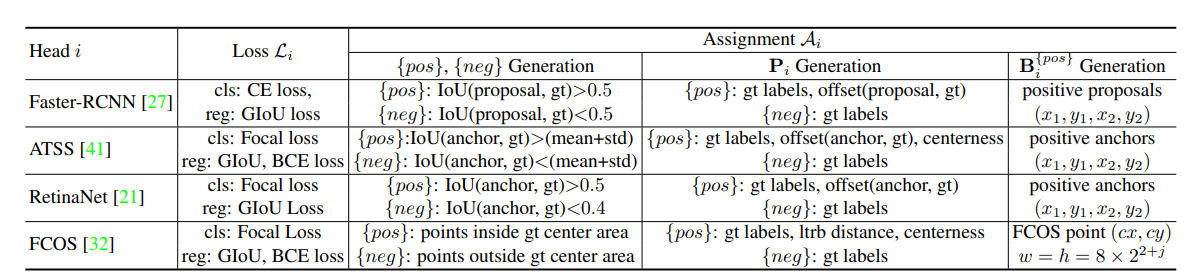
예를 들어 Faster R-CNN 보조헤드를 사용했다고 가정하겠습니다.
먼저 Encoder의 output 으로 FPN을 적용해 feature map을 얻습니다. 이후에는 Faster R-CNN 작동과 같은 방식으로 진행됩니다. Faster R-CNN은 feature map을 바탕으로 Region Proposal을 얻습니다. Region proposal 과 GT의 IoU 값이 0.5 이상이라면 ${pos}$ , 0.5 미만이면 ${neg}$ 로 판단합니다.
$P_{i}^{pos}$ 는 $P_{i}$ 중에서 ${pos}$ 라고 판단된 영역의 gt label 과 offset (proposal과 gt의 차이) 이 됩니다. $P_{i}^{neg}$ 는 gt label입니다. $B_{i}^{pos}$ 는 positive proposal 이라고 판정된 영역의 $x1,y1,x2,y2$ 값입니다. Object detection의 bounding box 역할입니다.
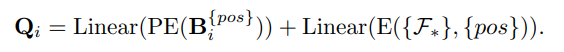
이렇게 얻은 정보를 바탕으로 positive Query, $Q_{i}$ 를 생성합니다. PE는 Positional Encoding, $F_{*}$ 은 * 번째 FPN, E는 $F_{*},{pos}$ $F_{*}$의 positive coordinate를 의미합니다.
Loss
Loss는 Encoder와 Decoder의 Loss에 대해 언급하고 있습니다. 아래는 Encoder의 Loss입니다.
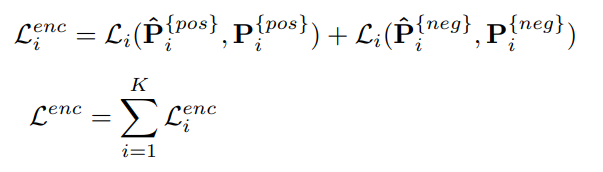
FPN으로 예측한 $\hat{P_{i}}$, 그리고 $\hat{P_{i}}$ 와 GT로 부터 얻어낸 $P_{i}$ 간의 Loss를 계산해서 더해주는 과정을 진행합니다. $i$는 i번째 인코더를 뜻합니다. Encoder의 최종적인 Loss값은 K개의 보조헤드와 Encoder간의 Loss의 합이 됩니다.
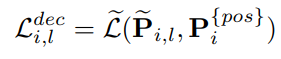
Decoder에서는 보조헤드의 output인 $\hat{P_{i}}$를 query 로 사용해서 output을 얻습니다. 위 수식은 l번째 decoder layer와 i번쨰 보조 헤드에서 얻어진 output을 $\tilde{P_{i,l}}$ 로 표시합니다. 따라서 해당 decoder에서 Loss는 output인 $\tilde{P_{i,l}}$ 와 보조헤드의 GT와 offset 정보를 가진 $P_{i}^{pos}$ 의 차이가 됩니다.
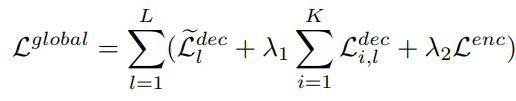
결과적으로 Co-DETR의 Loss는 위 수식과 같이 도출됩니다. 오른쪽 $\sum$ 은 위에서 언급한 encoder와 decoder의 loss에 대해서 summation을 진행합니다. $\lambda$는 loss의 균형을 맞춰주는 계수 입니다. 왼쪽 $\sum$ 의 $\tilde{L_{l}^{dec}}$ 는 l번째 decoder layer에서의 one-to-one set matching loss 입니다. 이 loss는 DETR의 것과 동일하게 적용됩니다.
Discriminability Score
Co-DETR 논문에서 지속적으로 강조하고 있는 내용은 DETR-based detector는 “너무 적은 수의 positive queries” 를 가진다는 것입니다. 쉽게 풀어서 쓰면 one to one set matching으로는 하나의 객체 당 하나의 positive query만 존재하고, 훈련 과정에서 이분 매칭에 의해 object가 매칭되는 query가 변할 수 있다는 것을 의미합니다.
Discriminability Score 는 이런 문제점들이 어떻게 모델에서 나타나는 지 분석한 하나의 지표입니다. 이 Score는 encoder의 latent feaure를 기반으로 계산됩니다. latent feature를 설명하기는 좀 어려운데 encoder의 output feature 공간 정도로 말할 수 있을 것 같습니다. 이 부분은 저도 정확하게 이해한 내용은 아니기 때문에 latent feature에 대해 따로 검색해보시면 좋을 것 같습니다.
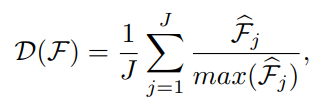
식에서 J는 위에서 언급한 “Encoder의 output으로 J개의 FPN을 만든다.” 의 J입니다. $\hat{F_{j}}$ 은 j번째 FPN에 L2 normalize를 적용한 것 입니다. 논문에서는 C X H X W 의 $F_{j}$ 에 L2-norm을 적용해 H X W 크기로 Resize한다고 합니다. 구하는 식은 normalize나 평균을 내는 식과 비슷해 보입니다.
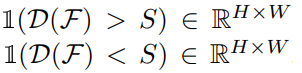
여기서 S는 threshold로 미리 설정된 임계값입니다. 임계값 보다 크면 1이 나오는 방식입니다. 아래 수식에 적용해보겠습니다.
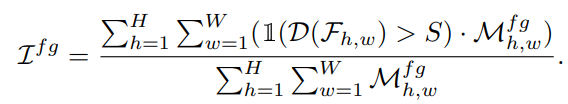
위 식은 foreground, 객체에 대해서 계산하는 식이므로 IoF가 됩니다. 여기서 $M_{h,w}^{fg}$ 는 (h,w)에 객체가 존재하면 1 아니면 0 의 값을 갖습니다.
H x W 의 모든 위치에 대해 방문하면서 h,w 의 Discriminability Score가 임계값 S를 넘었다면 1이 되고, 만약 h,w에 정말로 객체가 존재한다면 $M_{h,w}^{fg}$ 값 또한 1이 되어 (h,w) 위치에 대해서 1값을 갖게 됩니다. 분모는 실제로 객체가 존재하는 부분이면 +1을 해주는 식입니다.
간단하게 보면 분자는 (객체가 존재한다고 예측하면 1) * (객체가 존재하면 1) 이고 분모는 (객체가 존재하면 1) 됩니다. 따라서 분모가 항상 분자보다 큰 값을 갖게 되기 때문에 항상 1보다 작은 값이 결과로 나오게 됩니다. 객체가 존재하는 곳을 잘 예측할 수록 분자의 크기가 커지므로 큰 값을 가질수록 모델이 더 뛰어나다고 분석할 수 있습니다.
Experiment
실험에 대해서는 따로 사진을 캡쳐하지는 않았습니다. 논문에서는 Table2,3,4,5,6를 실험 결과로 Table7,8,9,10,11 을 Ablation study로 보여주고 있습니다. 간단하게 어떤 실험을 진행했는지만 확인해 보겠습니다.
- Table 2 - 보조헤드 개수(K)를 0~2개로 조정하면서 측정, K = 0 이면 보조헤드가 없는 원래 모델임을 의미합니다.
- Table 3 - backbone으로 Resnet50 대신 Swin-L 사용, 5 feature level을 사용했다고 하는데 정확한 의미는 모르겠습니다.
- Table 4 - backbone, multi-scale, query 수, epoch, model들을 다양하게 바꿔가며 실험한 총 결과
- Table 5 - Dataset을 COCO로 사용했을 때 기존 모델과의 비교입니다.
- Table 6 - Dataset을 LVIS로 사용했을 때 기존 모델과의 비교입니다.
- Table 7 - 보조 헤드 수를 변화 시켰을 때 메모리와 GPU에 대한 분석입니다.
- Table 8 - 보조 헤드 모델을 바꿔가며 실험한 결과입니다.
- Table 9 - 보조 헤드 aux, pos query 와 epoch을 바꿔가며 실험한 결과입니다.
- Table 10 - epoch 수를 증가시키며 실험한 결과입니다.
- Table 11 - Branch 모델과 K의 수를 조정해 실험한 결과입니다.
Conclusion
이 논문에서 중요하게 볼 것은 one-to-one set matching에서 발생하는 단점을 어떻게 극복하는가 인 듯 합니다.
DETR based 모델은 모두 one-to-one set matching을 사용하고, 논문에서는 2가지 단점을 언급하고 있습니다.
- 너무 적은 positive query - 하나의 GT 당 하나의 query만 존재
- 훈련 중 matching이 변하는 문제 - 이분 매칭에서 GT1과 query1이 매칭되었지만 다음 학습 때는 GT1과 query2가 매칭될 수 있음
이 단점을 시각적으로 보여주는 것이 논문에서의 IoF, IoB, Discriminability Score 입니다. 이러한 문제를 극복하기 위해 보조헤드를 통해 한 번 걸러진 positive query들을 입력으로 넣는 것을 해결책으로 제시합니다.
Co-DETR의 한계를 보자면 너무 model이 무거워진다는 것입니다. 어떻게 보면 DETR 의 목적이었던 ‘가벼운 모델’ 에서 좀 벗어났다고 볼 수 있습니다. Encoder, FPN, 보조 헤드까지 많은 모델들을 사용하기 때문입니다.
후기
이해하기 어려운 논문이었습니다… 전체적인 진행은 이해할만 했지만 positive query만을 decoder의 입력으로 넣는다라는 부분은 제대로 이해하지 못했습니다. 논문에 나오는 모르는 용어와 새로운 용어들이 더 힘들게 했던 것 같습니다. DETR의 문제점을 파악하기 위해서는 좋은 논문인 것 같습니다.